
Durant mes années de prépa, j’ai eu le loisir d’observer à quel point le tableau de la loi normale centrée réduite en décontenançait plus d’un. Entre ceux qui n’avaient pas la moindre idée de comment le lire, ceux qui se trompaient de colonne, ceux qui oubliaient la symétrie, ceux qui se plantaient de probabilité — et surtout ceux qui cumulaient ces erreurs. Autant vous dire que les copies d’examens regorgeaient de perles en tout genre. Le problème ? Penser qu’un seul tableau peut tout faire. Et oublier qu’un test bilatéral ne donne pas la même valeur critique qu’un unilatéral. Sauf que dans la vraie vie, les erreurs de valeurs critiques peuvent mener à des décisions coûteuses. Mais il y a pire : penser qu’un seul tableau suffit. Le tout, sur fond de méconnaissance des formules indispensables (Φ(x), φ(x), 1-Φ(x)). Et de refus catégorique d’utiliser une valeur négative (alors que Φ(x)=1-Φ(-x)). Car on a beau dire : la table N(0,1) demeure un indispensable pour qui veut s’approprier les logiques statistiques. On vous montre comment l’utiliser, avec notre table prête à l’emploi (PDF + Excel).
Tableau de la loi normale centrée réduite : téléchargement et lecture rapide
D’entrée de jeu, on arrête les fantasmes : le tableau de la loi normale centrée réduite (N(0,1)) ne se démode pas. Ce n’est pas une relique, c’est mon \"couteau suisse statistique\" – et il va vous sauver la mise là où Excel n’aura plus d’icône.
Téléchargez la table officielle en PDF haute définition (lisible sans loupe de bijoutier !) ici :
- Table N(0,1) PDF – Université de Nantes
Pour ceux qui veulent automatiser jusqu’au bout du stress, la version Excel pré-calibrée existe aussi (cherchez « Table N(0,1) Excel » sur les plateformes spécialisées, mais spoiler: aucune feuille ne vous fera comprendre la logique sous-jacente à votre place).

« Le tableau n’est pas mort, il a juste pris des couleurs numériques. »
En vrai proba-addict, je râle assez quand on me dit "Excel a tout tué". La table force à penser densité, répartition, et à lire ce que l’informatique cache : ce n’est pas un gadget mais la base pour comprendre ce qui se passe sous le capot des test-stat. Croire qu’on peut s’en passer ? Illusion dangereuse…
Lecture rapide : décoder ligne, colonne et centièmes en quelques secondes
Pour éviter l’effet "panne sèche devant la table", voici l’astuce chronométrée dont personne ne parle en amphi :
- Repérez la partie entière et le dixième du nombre recherché (exemple : pour 1,28 → ligne 1,2).
- Localisez la colonne correspondant au centième (ici : colonne 0,08).
- Lisez directement l’intersection : pour 1,28 → valeur trouvée = 0,8997. C’est plié.
Vous voyez ? Pas besoin de méditer devant les colonnes – la mécanique est brutale mais diablement efficace. Les statisticiens sérieux ne traînent jamais plus de 15 secondes sur ce genre d’opération.
Comment lire une table de loi normale centrée réduite pas à pas (méthode MECE)
Autant vous dire que ceux qui pensent qu’une table N(0,1) se lit au pif n’ont jamais goûté l’efficacité chirurgicale d’une méthode systématique. Voici le vrai mode d’emploi, découpé façon MECE (Mutually Exclusive Collectively Exhaustive) – la méthode que les cabinets facturent une fortune, alors que n’importe quel étudiant peut s’en sortir en 3 minutes chrono.
Étape 1 : repérer la partie entière et le dixième
Premier réflexe : prenez votre valeur x et isolez les deux premiers chiffres après la virgule. Pour x = 1,2, c’est « 1,2 » tout court (pas plus compliqué). C’est là qu’on pige l’intérêt de la table : la ligne correspond à la partie entière + dixième. Oubliez le reste pour l’instant, concentrez-vous sur cette base. Ceux qui cherchent encore « où est mon x ? » devraient relire la légende…
Étape 2 : ajouter le centième via la colonne
La beauté du truc ? Le centième se lit dans les colonnes. Pour x = 1,28, partez de la ligne « 1,2 », puis filez jusqu’à la colonne 0,08 – c’est la dix-huitième colonne (on ne compte pas les doigts ici). Pourquoi tant de précision sur le centième ? Parce que la densité φ(x) pique à mort si vous l’oubliez. La courbe est ultra-raide autour de zéro : une erreur de centième et hop, votre probabilité part à la dérive.
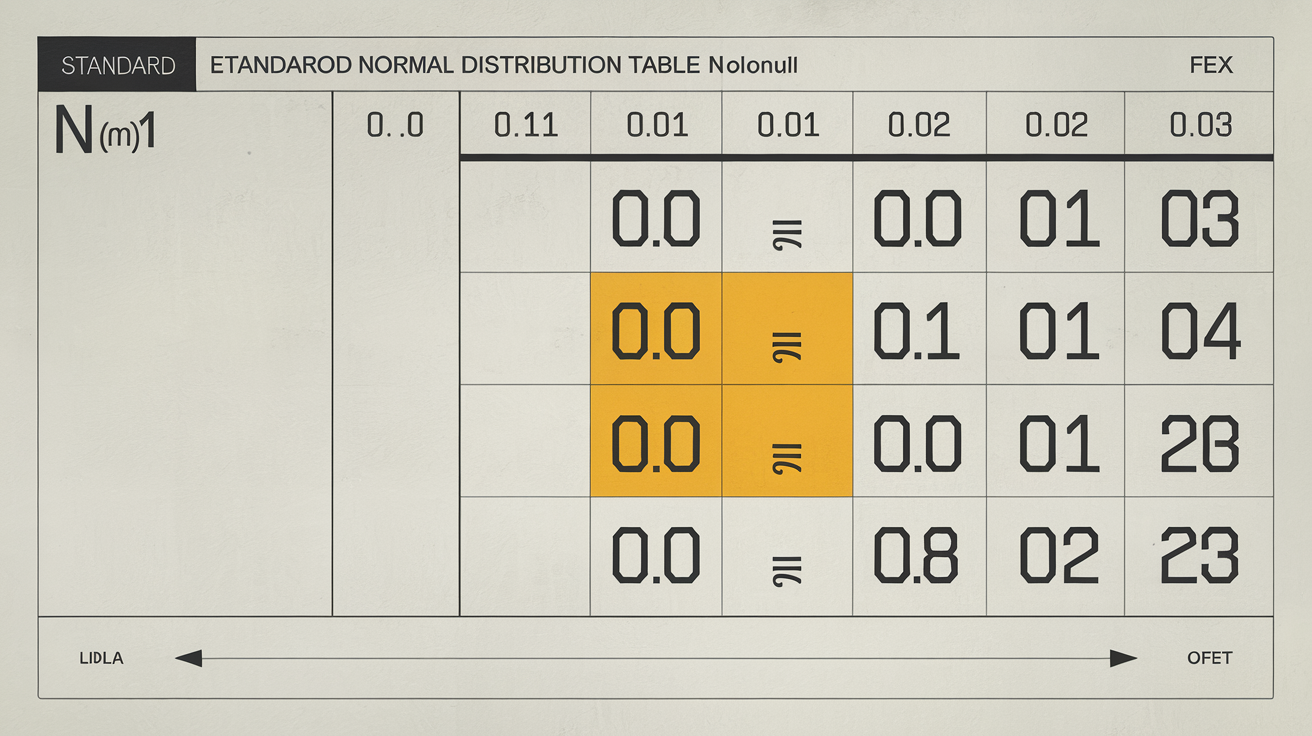
| 0.00 | 0.01 | 0.02 | 0.03 | |
|---|---|---|---|---|
| 0.0 | .5000 | .5040 | .5080 | .5120 |
| 0.1 | .5398 | .5438 | .5478 | .5517 |
| 0.2 | .5793 | .5832 | .5871 | .5910 |
Étape 3 : utiliser la symétrie pour les valeurs négatives Φ(x) = 1 - Φ(-x)
Voilà LE tour de passe-passe qui évite de paner devant un x négatif (genre -1,28). On prend Φ(-1,28), on feuillette sa table comme si c’était +1,28 (càd valeur positive), puis on applique direct : Φ(-x) = 1 – Φ(x). Donc ici : Φ(-1,28) = 1 – 0,8997 = 0,1003. Un nombre négatif ? Un coup de symétrie universelle et tout rentre dans l’ordre – même un examinateur grincheux n’a rien à dire.
Étape 4 : passer de la probabilité au quantile (lecture inverse)
Vous rêvez d’un z qui correspond pile-poil à une proba ? Facile : cherchez dans votre table la valeur la plus proche de P(Z ≤ z). Exemple pour P(Z ≤ z) = 0,975 : débusquez le chiffre dans toute la matrice et vous tombez sur z ≈ 1,96 (le fameux pourcentage « bilatéral » du test à 95% ; ceux qui posent encore la question peuvent changer de filière).

- Repérer ligne : partie entière + dixième ✔️
- Ajouter colonne : centième exact ✔️
- Symétrie des négatifs : Φ(x)=1−Φ(−x) ✔️
- Lecture inverse : retrouver z pour une proba choisie ✔️
Résumé efficace : La lecture d’une table N(0,1), ça s’apprend comme on dompte un Rubik’s Cube : en morceaux précis et jamais au hasard.
Formules indispensables de la loi N(0,1) à connaître avant de pianoter dans la table
Rendons à César ce qui appartient aux probabilités : la table, c’est joli, mais sans les formules qui la fondent, on fait du coloriage.
Fonction de répartition Φ(x) : définition et propriétés
La fameuse fonction de répartition Φ(x), c’est quoi ? Son travail : donner la probabilité cumulée d’obtenir une valeur inférieure ou égale à x pour une variable standardisée. Sa définition en langage matheux :
$
\Phi(x) = \int_{-\infty}^{x} \frac{1}{\sqrt{2\pi}} e^{-\frac{t^2}{2}} dt
$
Impossible d’exprimer cette intégrale avec une primitive simple — même WolframAlpha se casse les dents là-dessus. Vous pensiez pouvoir la calculer à la main ? Mauvaise pioche.
Propriétés principales à avoir tatouées dans le cortex :
- Continue partout (aucun saut de proba imprévu)
- Dérivable (sa dérivée est… la densité !)
- Toujours comprise entre 0 et 1 (bornée)
Densité φ(x)=1/√(2π)·e^{-x²/2} : pourquoi elle ne suffit pas
Autre star trop souvent confondue : la densité φ(x).
$
\varphi(x) = \frac{1}{\sqrt{2\pi}} e^{-x^2/2}
$
Ce n’est PAS une probabilité directe : c’est juste la hauteur de la courbe au point x, rien d’autre ! Pour passer à une véritable proba, il faut calculer l’aire sous cette densité sur un intervalle donné.
Dans mes premières années, j’ai vu des copies où des étudiants multipliaient φ(1) par 100 « pour faire un pourcentage »… Résultat : hors-sujet total, note sanctionnée par le sort (et par le prof).
Complémentarité et symétrie : Φ(x)+Φ(-x)=1, utilité pratique
On termine avec un raccourci que tout statisticien doit dégainer plus vite que son ombre :
$$
\Phi(x) + \Phi(-x) = 1
$$
Pourquoi ça tient debout ? Imaginez l’axe des abscisses : prendre x ou –x revient juste à retourner l’aire sous la courbe de part et d’autre du zéro. L’intégralité de la surface étant 1, si vous prenez ce qu’il y a à gauche (Φ(–x)), il ne reste plus que 1–Φ(–x) à droite — soit Φ(x). Bref : symétrie imparable.
{kind=link}
Exemples d’application concrets pour dompter la table N(0,1)
Calculer P(Z ≤ 1,28) : démonstration ligne par ligne
On va pas se mentir : si vous loupez une décimale ici, c’est la lose assurée. Je détaille l’opération — explication à quatre décimales chrono :
- Étape 1 : Ligne — Prenez « 1,2 », c’est la partie entière et le dixième (ligne 1,2).
- Étape 2 : Colonne — Ajoutez le centième « 0,08 » (colonne 0,08).
- Étape 3 : Intersection — Sur la table N(0,1), colonne et ligne croisées : 0,8997 (PAS 0,900 ou pire : 0,89… hein !).
- Étape 4 : Précision — On arrondit toujours à quatre décimales, sinon votre résultat claudique.
Liste de contrôle pour ne pas finir recalé :
- [x] Repérage exact des index de table (ligne/colonne)
- [x] Lecture sans approximation barbare
- [x] Résultat justifié : P(Z ≤ 1,28) = 0,8997
Trouver l’intervalle de confiance 95 % (±1,96) sans se tromper de colonne
Un mythe persistant chez les débutants : croire qu’on peut balancer la même valeur critique quel que soit le test. Erreur fatale.
« Unilatéral ? Bilatéral ? Votre correcteur n’a pas signé pour des devinettes. »
Soyons directs : pour un intervalle de confiance bilatéral à 95 %, la valeur à retenir est z = ±1,96. Si vous osez sortir un « 1,65 », c’est direct zéro (ça c’est pour les tests unilatéraux). La logique ? Bilatéral = on cherche le centile à gauche ET à droite de la moyenne (soit [2,5 %; 97,5 %]), donc z = ±1,96 couvre bien les deux queues.
| Confiance (%) | Test | Valeur critique z |
|---|---|---|
| 95 | bilatéral | ±1,96 |
| 95 | unilatéral | 1,64 |
| 99 | bilatéral | ±2,58 |
Anecdote vécue : j’ai vu un major de promo s’auto-saborder au concours en confondant les deux. Il multipliait ses chances d’échec… par deux. Littéralement.
Transformer X~N(μ,σ²) en Z : changement de variable affine et retour à l’échelle réelle
Marre des formules écrites à moitié sur la main ? Voici comment on passe d’une variable gaussienne quelconque à sa version standardisée — parce que X n’en fait qu’à sa tête tant que vous ne l’avez pas transformée.
Soit X suit une loi normale N(100;15²). On veut calculer P(X > 130).
- Formule canonique : $Z = \frac{X - \mu}{\sigma}$
- Ici : $Z = \frac{130 - 100}{15} = \frac{30}{15} = 2$
- On cherche donc P(Z > 2).
- Valeur dans la table (pour Z=2.00) : Φ(2.00) = 0,9772
- Donc P(Z > 2) = 1 – Φ(2) = 0,0228
- Interprétation directe : il n’y a que ~2% des valeurs au-dessus de 130 quand μ=100 et σ=15.
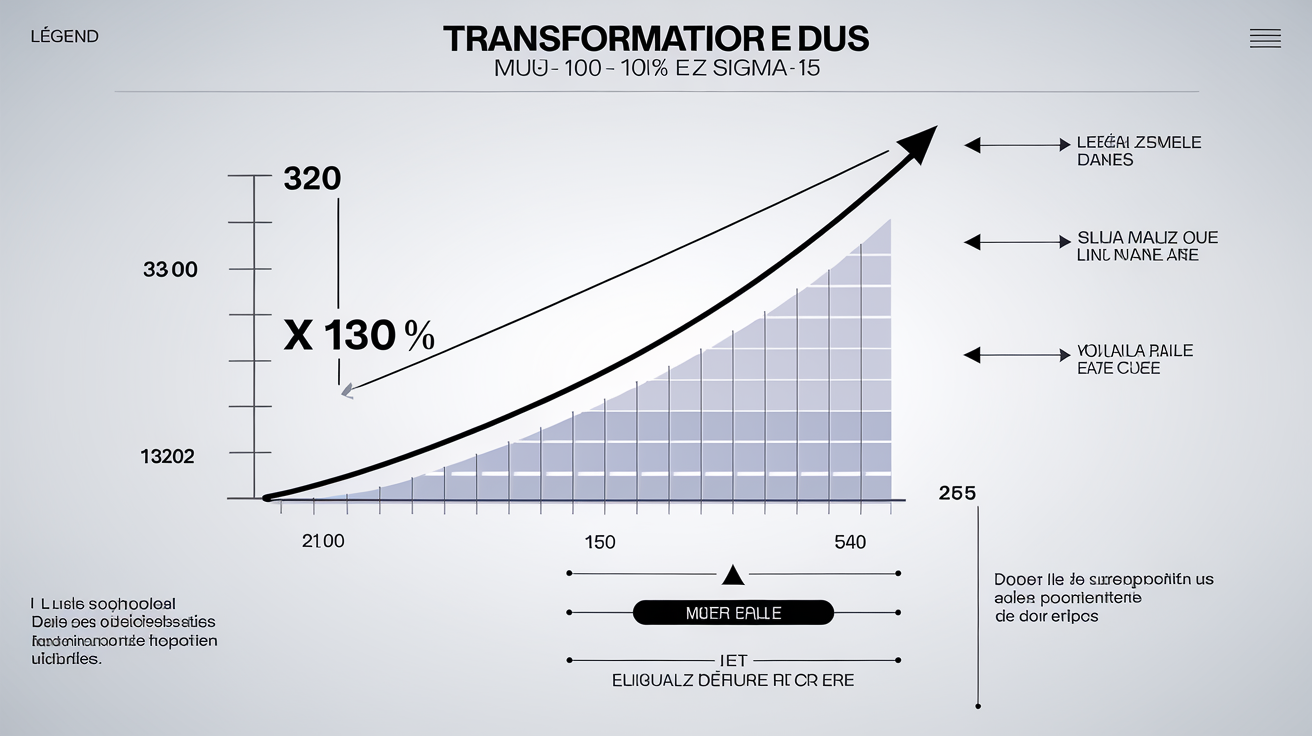
Ce passage obligatoire du monde réel vers le monde Z est LA clef pour dompter tous les exercices stats sérieux.
Erreurs classiques et pièges à éviter (retours d’expérience de copies d’examens)
Vous pensez que la table N(0,1) pardonne les approximations ? Mauvais calcul. Je vous sors ici trois boulets rouges qu’on retrouve dans 80% des copies ratées. Même ceux qui « savent faire » plongent dedans comme des amateurs.
Arrondis sauvages : pourquoi 0,841 et 0,842 ne sont pas interchangeables
Certains croient que tronquer ou arrondir d’un millième « ce n’est pas grave 00». C’est oublier que la frontière entre acceptation et rejet (genre à un seuil de 5 %) se joue à ±0,001 près.
Dans la vraie vie, ça veut dire quoi ? Prenez un seuil critique à Φ(z)=0,841 (soit z≈1), test unilatéral à 80 %. Vous basculez à 0,842 ? Ce n’est plus la même région de rejet, et donc potentiellement une erreur d’interprétation du résultat. La densité de probabilité ne pardonne rien : une décimale mal placée, et c’est le faux positif ou négatif assuré.
Probabilité complémentaire : oublier le 1-Φ(x) = hors-jeu automatique
Le grand classique reste l’oubli du complémentaire quand vous cherchez la proba d’être au-dessus d’une valeur (queue droite). À gober tout cru ? Jamais. Pour un test à droite, il faut systématiquement penser « 1-Φ(x) » :
- Si on cherche P(Z > a), c’est bien 1-Φ(a), pas Φ(a).
- Pour Z < –a : utilisez Φ(–a), ou symétriquement…
- Attention ! Oublier le complémentaire = résultat inversé sur toute la copie !
Mini-checklist express :
- [ ] Cas "au-dessus", queue droite ? → Penser 1–Φ(x)
- [ ] Cas "en-dessous", queue gauche ? → Direct Φ(x)
- [ ] Double seuil (bilatéral) ? → Cumuler les deux bouts avec complémentarité
Unilatéral vs bilatéral : confondre les deux = plantage statistique assuré
Ceux qui s’imaginent qu’une seule table/méthode suffit pour tous les tests n’ont jamais vu un examinateur lever les yeux au ciel…
Voici ce que ça donne en vrai, sans filtre marketing :
| Probabilité | Seuil critique unilatéral | Seuil critique bilatéral |
|---|---|---|
| 90 % | 1,28 | ±1,64 |
| 95 % | 1,64 | ±1,96 |
| 99 % | 2,33 | ±2,58 |
Rater le type de test revient littéralement à se tirer une balle statistique dans le pied. Les tests unilatéraux mesurent UNE extrémité ; bilatéraux jouent sur DEUX queues. Résultats opposés si on mélange—ça sent la colle fraîche au rattrapage.
H2 – Conclusion : les 5 réflexes pour apprivoiser définitivement la table de la loi normale
Impossible de clore sans matraquer ce qui doit rester vissé dans votre cortex (surtout si vous ne voulez pas finir corrigé à la hache). Ces cinq réflexes, pas un de moins, font barrage aux pires croyances grillées plus haut :

- Vérifier unilatéral ou bilatéral : c’est pas le même jeu, ni les mêmes valeurs critiques. Zéro tolérance pour l’erreur d’aiguillage.
- Toujours lire ligne-dixième PUIS centième : zapper cette mécanique ? C’est demander à se planter sur toute la colonne…
- Appliquer la symétrie Φ(x)=1–Φ(–x) : pas d’excuse, même une table « positive only » couvre tout avec cette astuce.
- Penser probabilité complémentaire (1–Φ(x)) : vouloir calculer P(Z>a) sans ce réflexe, c’est jouer à pile ou face avec sa note.
- Arrondir rigoureusement à 4 décimales : pas d’arrondi sauvage ou improvisé. Ici, chaque millième compte — et fait scorer… ou plomber le résultat !
Si vous croyez qu’une seule table remplace l’apprentissage de ces réflexes ? Mauvaise nouvelle : le tableau n’a jamais remplacé le cerveau.